 Вход
Вход Регистрация
Регистрация





Tranquility Tech III уже ждет вас!

Прошла примерно неделя с тех пор, как мы в первый раз сняли режим VIP-доступа в нашем новом дата-центре, и мы наконец можем сказать – ОПС УСПЕШЕН!
В тот насыщенный событиями понедельник, 29 февраля – все начиналось довольно жестко, но мы чертовски гордимся нашим достижением.
Я расскажу вам о нескольких днях, которые предшествовали этому переезду, как все происходило на самом деле, без лишних украшательств.
Цели
Без сомнений, «Tranquility Тech III» (усовершенствование и перенос главного сервера EVE Online) это самая масштабная миссия, которая ложилась на плечи операционного отдела CCP. Она включала в себя год планирования, обсуждения наилучших подходов, тонну бумажной работы, сложную трансферную логистику, наконец – будущий безопасный переезд с места на место.
В начале, мы внимательно посмотрели на сервер Tranquility, и выделили несколько элементарных и более серьезных возможностей для апгрейда.
Что мы задались целью сделать в рамках проекта TQ Tech III:
- Улучшить надежность и стабильность «железа»
- Повысить производительность всего кластера
- Улучшить сетевое подключение
- Перенести тестовые сервера в Исландию, для уменьшения разброса наших месторасположений
Наш текущий контракт с дата-центром заканчивался в последний день марта, и мы поставили себе цель закончить со всем 29 февраля, в «високосный день».
Начнем наш рассказ за несколько дней до «большого переезда», чтобы у вас сложилась полная картина событий.
Среда, 17 февраля – Узел «Эверест» выдал «синий экран смерти»
После многих лет надежной службы, узел «Эверест», ответственный за главный торговый хаб в игре, Житу – выдал «синий экран смерти», и весь рынок с игроками был перенесен на менее мощный узел.
Я просто хотел упомянуть это событие, так как узел превосходно работал и реально был рассчитан еще лет на 12 работы. К счастью, он вернулся к жизни после перезагрузки и снова продолжил работать после следующего даунтайма, уже до самого конца своего “дежурства”...
Среда, 24 февраля – Обновление операционной системы и версии SQL
24 февраля, в среду, у нас был расширенный даунтайм, во время которого мы обновляли базы данных сервера до Windows 2012 R2 и SQL 2014.
О деталях процесса нам расскажет CCP DeNormalized:
У чего есть 5 частей, что живет в 2 зданиях и разделено океанами и континентами?
Это кластер базы данных EVE Online.
Так вот, во время того самого расширенного даунтайма – мы сделали огромный шаг к будущему переносу нашего дата-центра.
Одна из главных проблем, которую нам нужно было решить – придумать, как перенести 2.5-терабайтную базу данных из одного дата-центра в другой, с кратчайшим временем ее выключения. Вдобавок к переносу, нам нужно было обновить версии ОС и SQL (с Windows 2008 R2 до Windows 2012 R2, и SQL 2012 Enterprise до SQL 2014 Enterprise).
Из этих двух проблем – больше всего нас волновало обновление до SQL 2014. Скорее даже не обновление, а план отступления, если нам придется откатываться обратно.
Видите ли, как только вы обновляете базу данных до новой версии SQL, вы уже не можете ее вернуть на старую. Единственный выход в данном случае – восстанавливать базу данных с той же или более ранней версии.
Мы решили, что менее рискованно будет обновить сервера с БД Tranquility до Win2012/SQL 2014 пока мы еще находимся в нашем текущем дата-центре. В день “большого переезда” нам придется меньше волноваться по этому поводу, а здесь и сейчас мы будем работать в знакомой среде, если вдруг что-то пойдет не так.
Вдобавок к этому, мы выбрали предпочтительный способ переноса базы данных в новый дата-центр – репликацию с использованием SQL AlwaysOn. Мы не могли так сделать раньше, так как сервера при этом должны работать на одной и той же версии ОС Windows.
Итак, план был следующий: объединить два отдельных экземпляра БД, по два узла в каждом, в один кластер Windows – и использовать AlwaysOn для синхронизации баз данных. Это дало бы нам возможность вернуться с нового дата-центра в старый, если бы нам вдруг захотелось (вообще очень не хотелось, но такое желание могло резко возникнуть!!!)!
Частично, это все заняло так много времени потому что мы еще добавили довольно впечатляющий (нам так казалось) способ тестирования во всю эту затею…
Мы начали с того, что отключили пассивный резервный узел нашего “боевого” кластера БД, обновили его до последней версии ОС, и подключили его к существующему Windows-кластеру в новом дата-центре, чтобы создать новый одноузловой SQL-кластер. Много работы ушло на покрытие одним Windows-кластером двух дата-центров, огромное спасибо нашим сисадминам и специалистам по сетям.
На заметку, работа без резервного узла – не то, чем мы обычно любим заниматься, но это было необходимо и не должно было продлиться дольше 24 часов.
Итак, в 09:00 GMT мы все выключили и продолжили! Сделали несколько вещей, таких как перенос IP со старого кластера на новый одноузловой кластер, и скопировали малые базы данных на новые диски. Касательно больших – мы просто переназначили SAN-разделы, и переподключили базы данных.
Это подводит нас к обновлению БД. Если мы подключаем экземпляр БД на SQL 2012 к нашему новому экземпляру на SQL 2014 – более старый экземпляр поддается обновлению, после чего он становится несовместимым со всеми предыдущими версиями SQL. Если по какой-либо причине тут что-то идет не так – у нас не остается выбора, кроме как делать восстановление данных из резервных копий, которые мы сделали ранее утром.
Нам бы не удалось просто переместить разделы базы назад на старый кластер (который все еще работал на одном узле, как наш запасной вариант).
Нам пришла в голову блестящая идея: перед тем как подключить разделы на SQL 2012 к новому 2014-кластеру, мы сделали SAN-снимки этих разделов. Затем, скормили эти снимки новому кластеру, подключили базы данных с дисков со снимками, и позволили им проапгрейдиться до новой версии. Потом запустились в режиме VIP-доступа, чтобы посмотреть, как все прошло. Все выглядело замечательно, так что мы отключили те базы данных: убрали снимки, и подключили к кластеру “реальные” диски, после чего повторили все заново после перезагрузки.
Все эти манипуляции заняли много времени, что внесло свою лепту в срыв назначенных сроков, но мы знали, что это того стоило!
Мы добавили диски к кластеру, назначили точки установки, подсоединили базы данных, и запустили Tranquility в VIP-режиме снова. Йухуу, все выглядело просто превосходно, так что мы “открыли ворота”!
Вскоре после открытия, мы вернулись к нашему старому кластеру и забрали у него последний узел. Добавили его к новому кластеру, и у нас снова есть резервирование!
В основном, все прошло гладко… Мы столкнулись с несколькими проблемами в плане включения дисков, и это привело к паре перезагрузок (каждая по 15 минут). Это стоило нам еще немного времени, но мы были удовлетворены тем, что успешно прошли этот этап.
CCP DeNormalized
Пятница, 26 февраля – Непредвиденный даунтайм базы данных
На этом этапе все было отлично, и мы готовились к включению, AlwaysOn работал как надо. Старый TQ остался стабильным после апгрейда БД, как мы и ожидали, на примере нескольких предыдущих апгрейдов.
Мы были уверены положении дел, пока в 19:50 GMT не начали получать в логах ошибки о так называемых «грязных страницах», копящихся в памяти SQL-сервера.
После краткого взгляда на проблему, в 20:15 GMT мы решили не играться с хот-фиксом в онлайн-режиме, а выключить TQ, чтобы избежать потери данных. Так что пока сервер был выключен, мы могли расследовать ситуацию вместе с Microsoft Premier Support.
Открываем заявку с наивысшим приоритетом, и примерно через 30 минут с нами по скайпу связался старший SQL-разработчик, которому мы расшарили наш монитор, чтобы дебаггинг шел быстрее, вместо того чтобы тянуть резину по e-mail / телефону.
Через некоторое время мы услышали «А, так это же EVE тут у вас! Надо бы мне вернуться поиграть снова!». Действительно приятно знать, что на другом конце линии сидит капсулёр!
У него был довольно крутой способ безопасно перенести эти «грязные страницы» из нашей RAM на диск, чтобы они остались у нас для бэкапа. Если по-простому – он уменьшал доступную RAM по маленьким кусочкам, чтобы количество «грязных страниц» уменьшилось, и мы могли продолжать с процессом бэкапа.
Для пущей уверенности, мы хотели сделать полную резервную копию TQ, пока он был в VIP-режиме, что заняло какое-то время. VIP-режим продлили до 23:50.
Корень зла, похоже, таился где-то в особенностях репликации БД, которые не должны были ни на что повлиять, но в IT же часто случаются всякие неожиданности.
Когда мы взяли проблему под контроль, то сразу провели оживленную дискуссию насчет того, как быть дальше. В итоге, победил менее рискованный вариант, и все согласились остановиться на варианте переноса БД с помощью восстановления из резервной копии.
Понедельник, 29 февраля – Високосный день, переезд
Так как мы бросили затею с SQL AlwaysOn, то подкорректировали наши ожидаемые сроки завершения работ, и были уверены, что в 14:00 GMT закончим.
В 08:00 GMT все были готовы к началу работ.
После отмашки на старт – атмосфера вокруг начала искрить, и царило всеобщее возбуждение по поводу предстоящего дня. В 09:00 TQ был выключен, последний раз в своем старом доме.
Мы начали выполнять все намеченные действия. Ощущая, что вполне укладываемся в график, приблизились к отметке времени 10:30 GMT. Запустили TQ в первый раз, и прогнали пару проверок, после чего снова выключили сервер.
К 11:00 мы запустили сервер целиком, включая все дополнительные компоненты вроде SSO, VGS, API и т.д., и наша команда разработки начала тестирование.
Было обнаружено множество мелких проблем, они устранялись на лету, примерно как если бы в реанимации у нас случился внезапный приток пациентов, и операционный отдел с разработчиками EVE оперировали их один за одним, в порядке степени тяжести, пока все сервисы до одного не заработали.
На данном этапе график начал поджимать, но мы не хотели идти по пути кратковременных решений проблем, нужно было все делать правильно. Если бы понадобилось – мы продлили бы даунтайм. Что и случилось: в 13:30 мы продлили его на час.
Вскоре после продления – все вроде бы встало на свои места, и в 14:20 мы запустили TQ в VIP-режиме, для последних проверок, чтобы быть на 100% уверенными во всем. Наконец, в 14:27 мы сняли VIP-режим. И наступил славный момент, когда мы увидели поток игроков, заходящих на сервер…
...и наше празднование длилось недолго, так как лаунчер забил тревогу, и веб-сайты начали ломиться от нагрузки. После того, как все немного поутихло, и логины игроков начали проходить корректно – вот тут-то и случился “большой бабах”. Совсем не в хорошем смысле.
БДЫЩ! ЦП баз данных TQ достигли 100% загрузки, без малейшего предупреждения или намека на то, что нагрузка увеличивается, практически мгновенно. Так что дальше – сказ о 5 запусках:
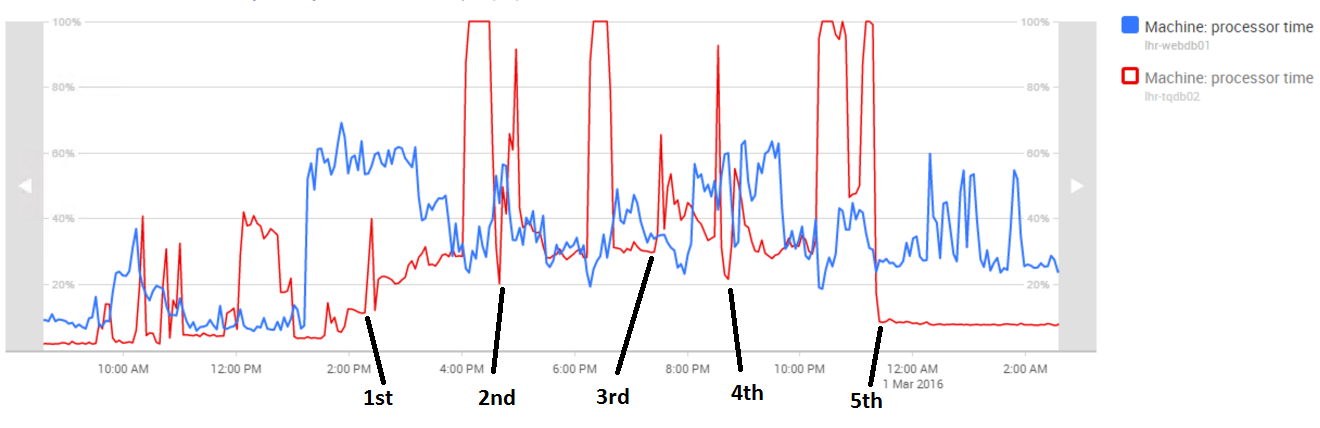
1. Тут мы были счастливы, что все прошло замечательно, реально счастливы.
- Через 90 минут работы мы наткнулись на внезапную 100% загрузку процессоров, диагностика показала, что все дело было в хранимой процедуре, которая пошла по очень плохому плану SQL-запроса.
- Мы видели, как это бывало на TQ ранее, но это случалось очень, просто крайне редко, и именно сегодня нам так не повезло. Мы выключили сервер, разобрались и снова его включили.
2. Мы очень боялись, что во второй раз это снова случится, так что пока отложили празднования
- И опять-таки лаунчер и веб-сайты начали ломиться от налета игроков, но все устаканилось, как и в первый раз.
- И после 90 минут мы снова наткнулись на такие же симптомы, только дело было уже в другом наборе хранимых процедур. Снова плохой план запроса ронял сервер, чего не должно было случиться, т.к. статистика по индексам в таблицах была недавно собрана.
- Мы объявили “красный код” и свистали всех наверх. Разработчики нашли решение проблемы с процедурами, хотя были согласны с разработчиками базы данных в том, что это все просто какой-то бред, и такого происходить не должно.
- Мы выключили сервер и применили хот-фикс.
3. Вскоре после третьего запуска, мы увидели, что рынок некорректно загружался, и множество ошибок полезли отовсюду – в основном, как следствие того, что мы пытались быстрее снова запустить сервер. Снова его выключили для проверок.
4. Тут мы уже приближались к ночи, и видели, что социальные медиа вполне объяснимо негодуют. Но находились и позитивные посты, которые бустили нам мораль, спасибо вам за это 
- Здесь мы еще были уверены, что хот-фикс нам поможет.
- Мы снова увидели падение производительности из-за лаунчера и веб-сайтов, но мы добавили ресурсов для фронт-энда, и у нас не было проблем с внезапным приростом пользователей.
- Мы наблюдали за обратным отсчетом таймера, установленного на 90 минут, и я не могу описать чувство, когда мы подошли к отметке 90… ииии, сервер опять рванул в 100% загрузку процессоров БД.
- Похоже, что предложенное разработчиками решение не работало, как и все остальные предпринятые меры. Мы начали подумывать об откате всего, но решили сначала перенести SQL-кластер на пассивный узел, и изменили настройки выделения места под RAM.
- Пришлось снова все выключать, и ход вещей принимал весьма грустный оборот, если не сказать больше.
5. Пятый раз – все как по маслу.
- Мы снова обнулили 90-минутный таймер. Передаем благодарности CCP Seagull, которая появилась вскоре после полуночи с добавкой RedBull’а и вкусняшек
- Опять воцарилось гнетущее ожидание, все следующие шаги обещали быть очень тяжелыми, если бы мы выбрали сценарий полного отката.
- В 23:47 мы были готовы к 5 запуску, и включили VIP-режим.
- Одна часть команды пошла домой, чтобы выйти уже днем, пока другие задремали в митинг-румах, чтобы подменять друг друга в течении ночи.
- Мы смотрели на счетчик, который дошел до 80 минут...85….88..….90……….91…………………….92, а потом достиг 2-часовой отметки, позже – 2.5-часовой, и наконец – 3-часовой отметки стабильной работы сервера, после чего все поняли, что мы наконец справились!
TQ работал гладко той ночью, и так как мы поставили себе целью запустить все 29 числа, а в ходе пятого запуска VIP-режим был снят до полуночи, получается, что мы достигли наивысшего уровня поставленных целей.
К сожалению, примерно в 09:00 GMT 1 марта, TQ выключил себя из-за того, что одну из настроек автоматического начала даунтайма забыли перевести на обычное значение 11 часов дня. Простейшая человеческая ошибка.
Вот как прошел тот понедельник, и я могу сказать вам, что пройти через проект такой сложности и такого масштаба – ужасно сложно, но и чрезвычайно отрадно, когда видишь плоды всех тяжелых трудов.
TQ Tech III – Текущее положение дел
Уже прошло несколько дней, и даже была одна битва в Hakonen, где бились в общей сложности около 1500 пилотов. Битва проходила на одном из 25 «стандартных» узлов TQ Tech III. Шесть усиленных узлов все еще ожидают надлежащей битвы. Так что мы ждем с нетерпением, когда сможем посмотреть, на что же они способны.
Мы уже видели отчеты о положительном и негативном фидбэке, который помог нам в тонкой настройке «железа».
Чтобы продемонстрировать степень улучшения, вот вам графики от CCP Quant:
Изменения в производительности
Результатом внедрения TQ Tech 3 вместе с “Brain in a box” стало заметное улучшение производительности, но насколько заметное? Вот графики того, как изменилась нагрузка на сервер, чтобы вы получили представление о масштабах, и о том, как эти изменения повлияют на ваш геймплей:
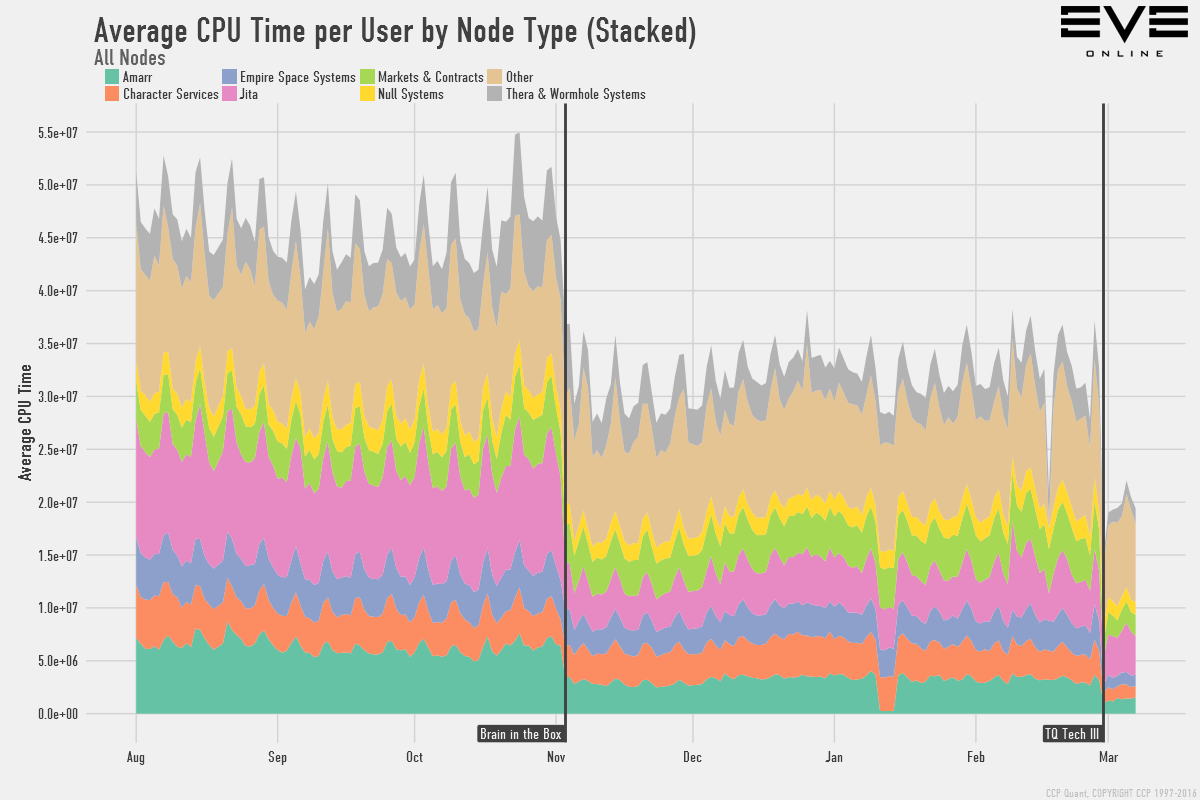
Здесь показано общее среднее процессорное время в расчете на пользователя, по каждому типу серверного узла. Не сильно вчитывайтесь в цифры, они абстрактные и призваны лишь предоставить шкалу для сравнения. Среднее процессорное время в расчете на одного пользователя теперь составляет примерно 40% от того, каким оно было до запуска “Brain in a box”. Далее – частные случаи этого графика, для геймплея в империи, червоточинах и торговли, чтобы продемонстрировать несколько примеров:
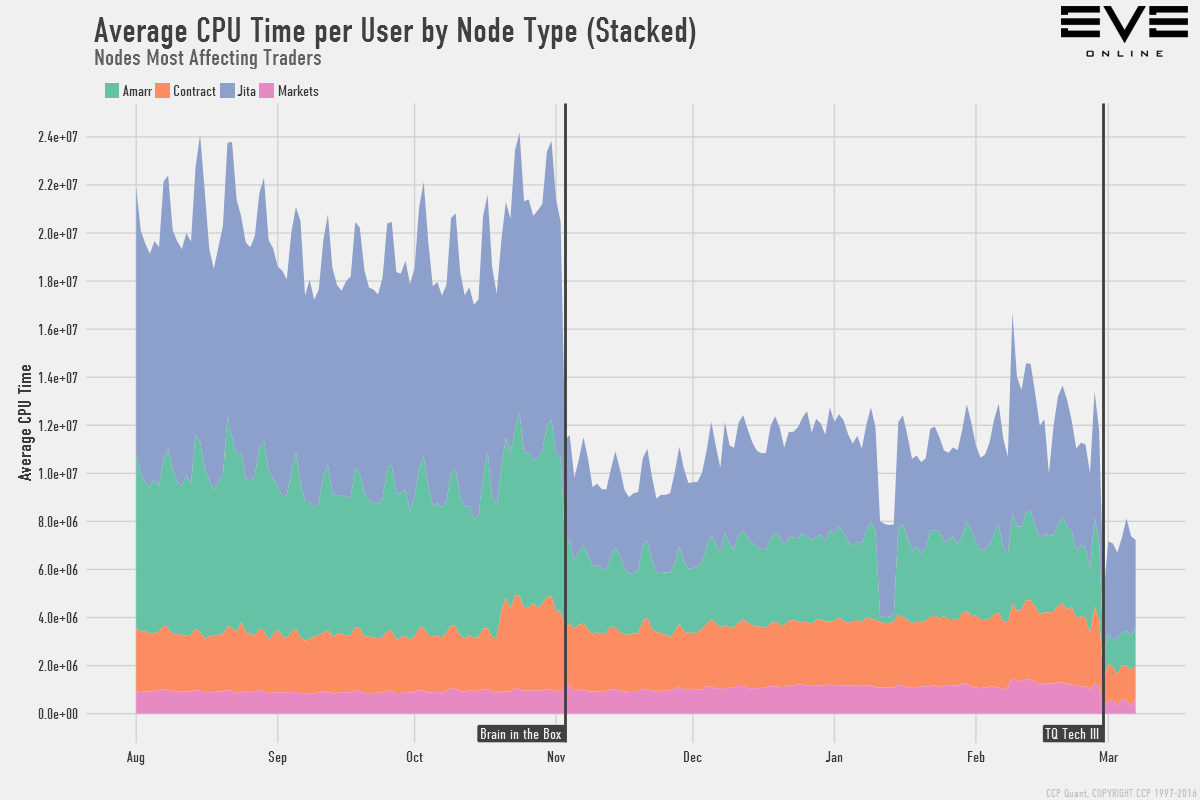

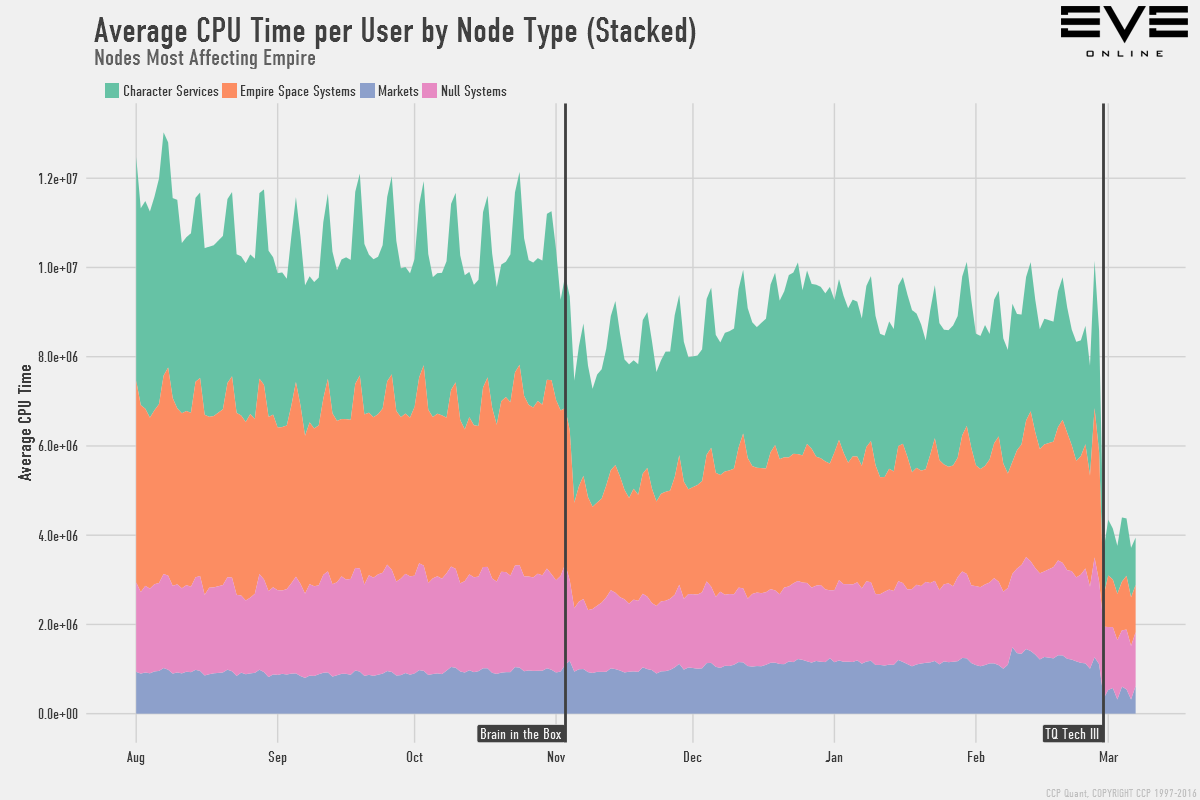
Вы можете увидеть, насколько лучше будет отклик, который вы можете ожидать от маркета в Жите, к примеру. Эти изменения не только ускоряют общий отклик сервера, но и делают большие флотовые бои более жизнеспособными.
Вот очень интересный график, показывающий нагрузку на процессор и коэффициент замедления времени (Time Dilation) узла, на котором была размещена система Hakonen, когда в ней происходил бой 2 марта:
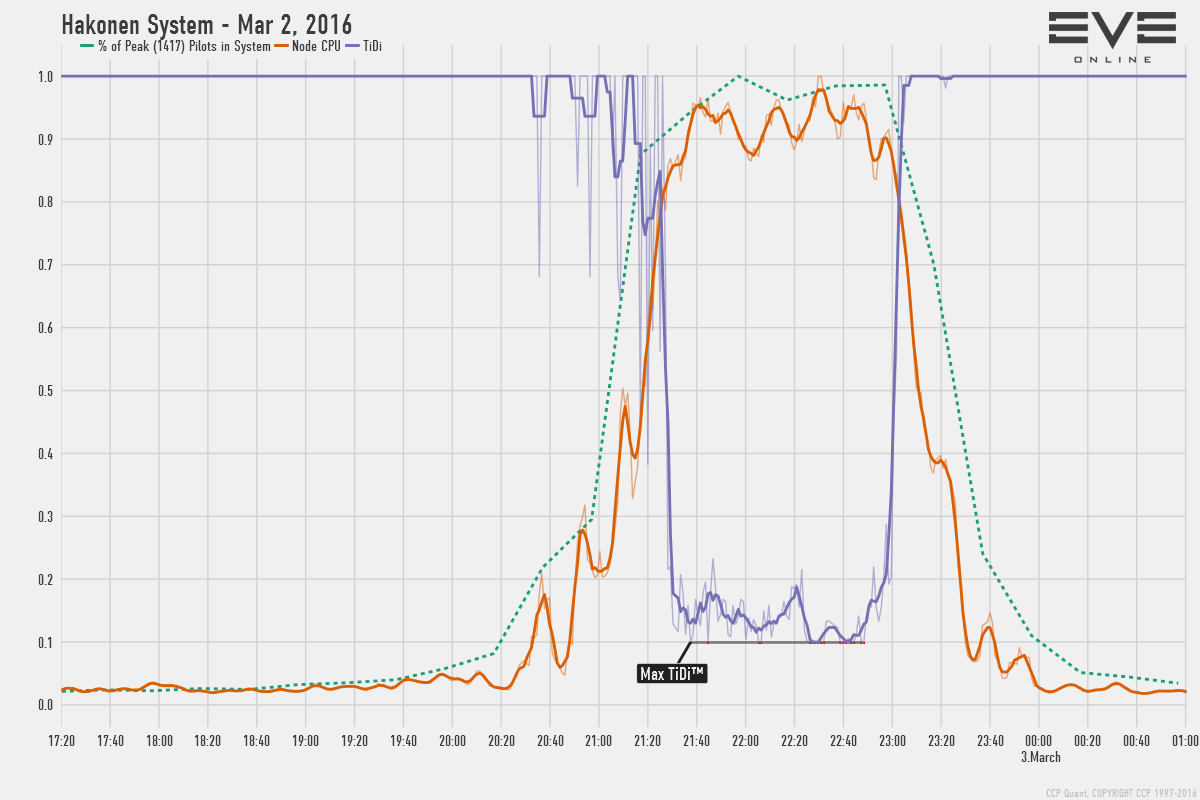
Мы не направляли дополнительные мощности на поддержку этой системы, и так как это лоусек – производилось большое количество дополнительных вычислений, которые нужны для системы отслеживания преступлений, стендингов, работы гейтовых орудий и т.д.
Замедление времени не может падать ниже 10% от нормального, так как после этого очередь задач на сервере начинает переполняться, и игроки начнут испытывать вещи вроде неработающих модулей и т.п, что в итоге приведет к падению узла.
Глядя на этот график, мы видим, что замедление времени падало до 10% несколько раз, но в общей сложности – не более пары раз по 5 минут. Это значит, что все кто испытывал какие-то трудности, скорее всего испытывали их именно в эти периоды. Пока замедление больше 10% – узел успешно обрабатывает очереди задач с помощью замедления, и как мы тут видим, вместо постоянного 10% уровня, у него получалось оставаться где-то между 10-20% на пике событий битвы.
CCP Quant
Немного о будущем
Сейчас производительность сервера впечатляет, но мы еще даже близко не закончили с нашей новой сетевой системой, фокусируясь на достижении малого пинга и высокой надежности.
В частности, мы планируем использовать автоматизированное сетевое решение для динамической маршрутизации на основе BGP, которое проверяли еще когда TQ был на старом сервере. Оно активно ищет лучшие сетевые маршруты, чтобы перенаправлять соединения через подсети, если найдется лучший маршрут для вас. Это все происходит без закрытия сокета, естественно. Тесты прошли с отличными результатами.
Также, мы решили избавиться от одного из наших сетевых провайдеров, и подписали договор с другим. В основном, если провайдер недостаточно хорош для игроков, мы перестаем с ним сотрудничать, чтобы найти кого-то понадежнее, готового принять наши вызовы.
Автоматизированное сетевое BGP-решение, в свою очередь, может вступить в работу в любой день, так что следите за блогами.
У нас теперь более мощные граничные маршрутизаторы. Вот письмо от одного из наших сетевых магов:
«Граничный маршрутизатор в новом дата-центре теперь получает в общей сложности 2.9 миллиона BGP-маршрутов от 23 пиров. Пока вычисляются наилучшие таблицы маршрутизации на этом новом роутере – процент загрузки процессора примерно равен 8%, тогда как старый роутер в Telecity для аналогичного пересчета таблицы маршрутизации задействовал все 100% мощности. Это довольно приличное увеличение производительности!»
Теперь наши глаза приклеены ко всевозможным инструментам, которые показывают, в каком месте становится «горячо» в плане нагрузки. С гибкостью TQ Tech III – у нас есть куда больший контроль над балансировкой нагрузки, что просто отлично, учитывая, что выпуск дополнения «Цитадель» уже виден на горизонте, со всеми его улучшениями кораблей капитального класса и новой механикой захвата и защиты структур. Мы продолжим все тут настраивать, чтобы улучшить ваш опыт полетов в Новом Эдеме.
От имени операционного отдела, я с гордостью и официально приглашаю вас на Tranquility Tech III
CCP Gun Show
![]() Примечание переводчика
Примечание переводчика
Сообщение отредактировал Cloned Mark: 26 March 2016 - 14:45
 Наверх
Наверх









 (кстати там почти та же система как еве аля грид, только работало это как обзор и из-за этого лагов было меньше)
(кстати там почти та же система как еве аля грид, только работало это как обзор и из-за этого лагов было меньше)

 а не переменные в тексте)
а не переменные в тексте)



